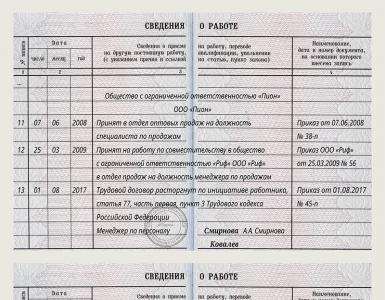
Ogni amminoacido è codificato da un gruppo di. Il principio della codifica delle sequenze di aminoacidi - Ipermercato della conoscenza. Storia delle idee sul codice genetico
È un metodo in cui le informazioni sulla sequenza di venti aminoacidi vengono codificate utilizzando una sequenza di quattro nucleotidi.
Proprietà del codice genetico
1) Triplice
Un amminoacido è codificato da tre nucleotidi. Nel DNA sono chiamati tripletta, nell'mRNA - codone, nel tRNA - anticodone. Ci sono 64 triplette in totale, 61 delle quali codificano per aminoacidi e 3 sono segnali di arresto: mostrano al ribosoma il punto in cui dovrebbe fermarsi la sintesi proteica.
2) Degenerazione (ridondanza)
Ci sono 61 codoni che codificano per gli amminoacidi, ma solo 20 amminoacidi, quindi la maggior parte degli amminoacidi sono codificati da più codoni. Ad esempio, l'amminoacido alanina è codificato da quattro codoni: HCU, HCC, HCA, HCH. L'eccezione è la metionina, è codificata da un codone AUG - negli eucarioti questo è il codone di inizio durante la traduzione.
3) Inequivocabilità
Ogni codone codifica per un solo amminoacido. Ad esempio, il codone HCU codifica solo un amminoacido: l'alanina.
4) Continuità
Non ci sono separatori (“segni di punteggiatura”) tra le singole terzine. Per questo motivo, quando un nucleotide viene cancellato o inserito, si verifica uno “spostamento del frame di lettura”: a partire dal sito della mutazione, la lettura del codice della tripletta viene interrotta e viene sintetizzata una proteina completamente diversa.
5) Versatilità
Il codice genetico è lo stesso per tutti gli organismi viventi sulla Terra.
Lezione 5. Codice genetico
Definizione del concetto
Il codice genetico è un sistema per registrare informazioni sulla sequenza degli amminoacidi nelle proteine utilizzando la sequenza dei nucleotidi nel DNA.
Poiché il DNA non è direttamente coinvolto nella sintesi proteica, il codice è scritto nel linguaggio dell'RNA. L'RNA contiene uracile invece di timina.
Proprietà del codice genetico
1. Triplice
Ogni amminoacido è codificato da una sequenza di 3 nucleotidi.
Definizione: una tripletta o codone è una sequenza di tre nucleotidi che codificano un amminoacido.
Il codice non può essere monoplet, poiché 4 (il numero di diversi nucleotidi nel DNA) è inferiore a 20. Il codice non può essere doppietto, perché 16 (il numero di combinazioni e permutazioni di 4 nucleotidi di 2) è inferiore a 20. Il codice può essere tripletta, perché 64 (il numero di combinazioni e permutazioni da 4 a 3) è superiore a 20.
2. Degenerazione.
Tutti gli aminoacidi, ad eccezione della metionina e del triptofano, sono codificati da più di una tripletta:
2 AK per 1 tripletta = 2.
9 AK, 2 triplette ciascuna = 18.
1 AK 3 triplette = 3.
5 AK di 4 triplette = 20.
3 AK di 6 triplette = 18.
Un totale di 61 triplette codificano 20 aminoacidi.
3. Presenza di segni di punteggiatura intergenici.
Definizione:
Gene - una sezione di DNA che codifica una catena polipeptidica o una molecola tRNA, RRNA osRNA.
GenitRNA, rRNA, sRNAle proteine non sono codificate.
Alla fine di ciascun gene che codifica per un polipeptide c'è almeno una delle 3 triplette che codificano i codoni di stop dell'RNA, o segnali di stop. Nell'mRNA hanno la seguente forma: UAA, UAG, UGA . Terminano (terminano) la trasmissione.
Convenzionalmente il codone appartiene anche ai segni di punteggiatura AGOSTO - il primo dopo la sequenza leader. (Vedi Lezione 8) Funziona come una lettera maiuscola. In questa posizione codifica la formilmetionina (nei procarioti).
4. Inequivocabilità.
Ciascuna tripletta codifica per un solo amminoacido o è un terminatore della traduzione.
L'eccezione è il codone AGOSTO . Nei procarioti, nella prima posizione (lettera maiuscola) codifica la formilmetionina, in qualsiasi altra posizione codifica la metionina.
5. Compattezza o assenza di segni di punteggiatura intragenici.
All'interno di un gene, ciascun nucleotide fa parte di un codone significativo.
Nel 1961 Seymour Benzer e Francis Crick dimostrarono sperimentalmente la natura tripletta del codice e la sua compattezza.
L'essenza dell'esperimento: mutazione “+” - inserimento di un nucleotide. Mutazione "-" - perdita di un nucleotide. Una singola mutazione "+" o "-" all'inizio di un gene rovina l'intero gene. Anche una doppia mutazione "+" o "-" rovina l'intero gene.
Una tripla mutazione “+” o “-” all’inizio di un gene ne rovina solo una parte. Una mutazione quadrupla “+” o “-” rovina nuovamente l’intero gene.
L'esperimento lo dimostra Il codice viene trascritto e non ci sono segni di punteggiatura all'interno del gene. L'esperimento è stato condotto su due geni fagici adiacenti e ha mostrato, inoltre, presenza di segni di punteggiatura tra i geni.
6. Versatilità.
Il codice genetico è lo stesso per tutte le creature che vivono sulla Terra.
Nel 1979 Burrell aprì ideale codice dei mitocondri umani.
Definizione:
“Ideale” è un codice genetico in cui è soddisfatta la regola di degenerazione del codice quasi-doppietto: se in due triplette i primi due nucleotidi coincidono e il terzo nucleotide appartiene alla stessa classe (entrambi sono purine o entrambi sono pirimidine) , allora queste triplette codificano per lo stesso amminoacido .
Ci sono due eccezioni a questa regola nel codice universale. Entrambe le deviazioni dal codice ideale nell'universale si riferiscono a punti fondamentali: l'inizio e la fine della sintesi proteica:
Codone | universale codice | Codici mitocondriali |
|||
Vertebrati | Invertebrati | Lievito | Impianti |
||
FERMARE | FERMARE |
||||
Con l'UA | |||||
AGA A | FERMARE | ||||
FERMARE | 230 sostituzioni non cambiano la classe dell'amminoacido codificato. alla lacerabilità. Nel 1956 Georgiy Gamow propose una variante del codice sovrapposto. Secondo il codice Gamow ogni nucleotide, a partire dal terzo nel gene, fa parte di 3 codoni. Quando il codice genetico fu decifrato, si scoprì che non si sovrapponeva, cioè Ogni nucleotide fa parte di un solo codone. Vantaggi di un codice genetico sovrapposto: compattezza, minore dipendenza della struttura proteica dall'inserimento o dalla cancellazione di un nucleotide. Svantaggio: la struttura proteica dipende fortemente dalla sostituzione dei nucleotidi e dalle restrizioni sui vicini. Nel 1976 fu sequenziato il DNA del fago φX174. Ha DNA circolare a filamento singolo costituito da 5375 nucleotidi. Era noto che il fago codificava 9 proteine. Per 6 di essi sono stati identificati i geni situati uno dopo l'altro. Si è scoperto che c'è una sovrapposizione. Il gene E si trova interamente all'interno del gene D . Il suo codone iniziale risulta da uno spostamento del fotogramma di un nucleotide. Gene J inizia dove finisce il gene D . Codone iniziale del gene J si sovrappone al codone di stop del gene D come risultato dello spostamento di due nucleotidi. La costruzione è chiamata “reading frameshift” mediante un numero di nucleotidi non multiplo di tre. Ad oggi, la sovrapposizione è stata dimostrata solo per pochi fagi. Capacità informativa del DNA Ci sono 6 miliardi di persone che vivono sulla Terra. Informazioni ereditarie su di loro 4x10 13 pagine di libro. Queste pagine occuperebbero lo spazio di 6 edifici NSU. 6x10 9 spermatozoi occupano mezzo ditale. Il loro DNA occupa meno di un quarto di ditale. | ||||
Il segno del creatore Filatov Felix Petrovich
Capitolo 496. Perché ci sono venti amminoacidi codificati? (XII)
Perché ci sono venti aminoacidi codificati? (XII)
A un lettore inesperto può sembrare che gli elementi della macchina per la codifica genetica siano stati descritti in modo così dettagliato nel capitolo precedente che alla fine della lettura ha persino cominciato a stancarsi in qualche modo, sentendo che l'inizio del libro, che in qualche modo lo ha incuriosito , si trasforma nelle pagine di un libro di testo di scuola superiore che può scoraggiare chiunque ricordi la sua scuola natale. Il lettore esperto, al contrario, conosce bene tutto ciò che è stato detto e, peccaminosamente, sta pensando se scrivere lui stesso un libro di testo più recente - per le stesse classi senior. Senza pensare a divertire il mondo orgoglioso– in altre parole, senza voler annoiare nessuno dei due, l'Autore tiene a sottolineare di aver capito: il diavolo è nei dettagli. Ma ce ne sono così tanti nella biologia molecolare che qualsiasi formalizzazione sembra una semplificazione scandalosa. Capita spesso, però, che la tentazione di formalizzare sia irresistibile, e qui l'Autore non può negarsi il piacere di citare ancora una volta il filosofo spagnolo José Ortega y Gasset:
« Il colore grigio è ascetico. Questo è il suo simbolismo nel linguaggio quotidiano, e Goethe accenna a questo simbolo: "La teoria, amico mio, è secca, ma l'albero della vita diventa verde". Il massimo che può fare un colore che non vuole essere colore è diventare grigio; ma la vita sembra un albero verde - che stravaganza!... L'elegante desiderio di preferire il colore grigio alla meravigliosa e contraddittoria stravaganza cromatica della vita ci porta a teorizzare. In teoria, scambiamo la realtà con quell'aspetto di essa che sono i concetti. Invece di viverci, ci pensiamo. Ma chissà se dietro questo evidente ascetismo e ritiro dalla vita, che è il pensiero puro, c'è la forma più completa di vitalità, il suo lusso più alto?
- Bravo, José! Questo è esattamente quello che penso, ne sono addirittura convinto.
La parte principale del libro, sebbene di volume più piccolo, alla quale si rivolge ora l'Autore, è dedicata alla formalizzazione, alla teorizzazione, agli schemi e alla progettazione del codice genetico. La prima ipotesi formale sulla struttura del codice genetico fornisce una possibile risposta alla domanda sul perché ci sono esattamente venti amminoacidi codificati .
Nel 1954 Gamow fu il primo a dimostrare che " quando 4 nucleotidi vengono combinati in triplette, si ottengono 64 combinazioni, il che è abbastanza per registrare informazioni ereditarie" Fu il primo a proporre che gli amminoacidi siano codificati da triplette di nucleotidi e espresse la speranza che ciò fosse possibile “Alcuni degli scienziati più giovani vivranno abbastanza per vederlo [il codice genetico] decifrato”. Nel 1968, gli americani Robert Holley, Har Korana e Marshall Nirenberg ricevettero il Premio Nobel per aver decifrato il codice genetico. Il premio è stato assegnato dopo la morte di George Gamow avvenuta nello stesso anno quattro mesi prima.
I numeri 64 (capacità di codifica teorica) e 20 (capacità di codifica effettiva, cioè il numero di amminoacidi codificati) formano il rapporto delle regole combinatorie per posizionamenti e combinazioni con ripetizioni: numero A di posizionamenti (insiemi ordinati) con ripetizioni da r (r = 3; dimensione del codone) elementi di un insieme M contenente k (k = 4; numero di basi) elementi è uguale a
Akr= kr= A43= 64,
e il numero C di combinazioni con ripetizioni di k elementi in r, cioè qualsiasi sottoinsieme di 3 elementi di un insieme contenente 4 elementi, è uguale a:
Con kr= [(k+r-1)!] : = C43= 20.
Ciò porta immediatamente all'idea che l'evoluzione del codice genetico potrebbe iniziare con la fase di codifica "set", quando il prodotto era codificato non dalla sequenza di basi triplette, ma dal loro set, cioè due gruppi di codoni, come, ad esempio, SAAA, COME UN, AAS O TGC, GCC, GCT, Condizioni generali, CTG, CGT erano funzionalmente equivalenti (all'interno del gruppo) e ciascuno dirigeva la sintesi dello stesso amminoacido. Considerazioni simili vengono in mente leggendo il lavoro di Ishigami e Nagano (1975), con la loro idea che ogni amminoacido primario potrebbe corrispondere ad un ampio intervallo di codoni, e di Folsom (1977) e Trainor (1984), con la loro idea di permutazione di base all'interno della tripletta. Ovviamente, un numero inferiore di codoni non forniva la necessaria diversità di prodotti, e b O Il resto era ridondante e, almeno, non corrispondeva al numero di aminoacidi oggi conosciuti. Un tempo abbiamo anche dato un contributo (molto) modesto a queste idee, notando che il numero di combinazioni di 4 Di 3 illustrato con ripetizioni per il numero di stati quantistici di un gas Bose a tre particelle con quattro probabili autostati quantistici54.
Successivamente, Gamow propose uno schema per implementare il codice genetico, che prevedeva l'assemblaggio di un polipeptide direttamente su una molecola di DNA. Secondo questo modello, ogni amminoacido è posto in una rientranza rombica tra quattro nucleotidi, due per ciascuna catena complementare. Sebbene un tale diamante sia costituito da quattro nucleotidi e, quindi, il numero di combinazioni sia 256, a causa delle restrizioni associate ai legami idrogeno dei residui nucleotidici, sono possibili solo 20 varianti di tali diamanti. Questo schema, chiamato codice diamante, suggerisce una correlazione tra residui amminoacidici successivi, poiché due nucleotidi compaiono sempre in due diamanti adiacenti (codice sovrapposto). Ulteriori ricerche hanno tuttavia dimostrato che anche questo modello Gamow non concorda con i dati sperimentali.
Se la capacità del codice genetico fosse utilizzata senza riserve, cioè ad ogni tripletta corrispondesse un solo amminoacido, la sua sicurezza sarebbe molto dubbia: qualsiasi mutazione nucleotidica potrebbe essere catastrofica. Nella versione attuale un terzo delle mutazioni puntiformi casuali si verificano nelle ultime lettere dei codoni, metà delle quali (codoni dell'ottetto IO) non è affatto sensibile alle mutazioni: la terza lettera del codone può essere una qualsiasi delle quattro - T, C, UN O G. Resistenza alle mutazioni puntiformi dei codoni dell'ottetto IIè in gran parte determinato da due fattori: (1) la possibilità di sostituzione arbitraria della terza base (sebbene quando si scelga solo tra due - purine o pirimidine), che non cambia affatto l'amminoacido codificato, e (2) la possibilità di sostituire le purine con le pirimidine e viceversa, il che preserva un'idrofilicità/idrofobicità simile dei prodotti, sebbene non ne preservi la massa. Pertanto, la Natura utilizza un “contraccolpo” di grande successo chiamato degenerazione codice, quando il carattere codificato corrisponde a più di un carattere di codifica.
L'evoluzione ha successivamente perfezionato le funzioni di ciascuna delle tre basi del codone, che alla fine ha portato alla rigorosa tripletta di soli due codoni: ATG- Per M(metionina) e TTG- Per W(triptofano). Basato solo sulla capacità della tripletta di codificare uno amminoacido, classifichiamo questi due come il gruppo di degenerazione IO. Quando il prodotto è codificato da un doppietto fisso di basi e il terzo può essere uno qualsiasi di quattro possibile e funge effettivamente da separatore tra doppietti funzionali, parlano di aminoacidi del gruppo degenerato IV; Esistono otto amminoacidi di questo tipo: alanina, UN, arginina, R, valina, V, glicina, G, leucina, l, prolina, P, serina, S, treonina, T. Il codone generalizzato per ciascun amminoacido di questo gruppo, ad esempio la leucina, è scritto come segue: STN (N -base arbitraria).
Dodici prodotti codificati appartengono al gruppo di degenerazione II; in questo gruppo la terza base è una delle due (non da quattro, come nel caso precedente): si tratta di purina ( R), cioè adenina, UN, o guanina, G, – o pirimidina ( Y), cioè citosina, CON, o timidina, T. Questo gruppo comprende tre amminoacidi a noi familiari dal quarto gruppo di degenerazione: arginina, leucina e serina, ma qui codificati da altri doppietti, due coppie: asparagina / acido aspartico ( N/D) e glutammina/acido glutammico ( Domande/E), così come l'istidina H, lisina K e tirosina Y. Il codice genetico universale include in questo gruppo anche la cisteina. CON, con le sue due triplette di codifica – TGC E TGT, cioè con una terza pirimidina, oltre a tre codoni di stop, ETICHETTA, TAAA E TGA, che fungono solo da segni di punteggiatura per contrassegnare la fine di un gene ma non codificano alcun amminoacido. Il codone generalizzato per gli amminoacidi di questo gruppo, ad esempio l'asparagina, è scritto come segue: AAY e acido aspartico – G.A.R..
Infine, il gruppo di degenerazione III contiene isoleucina, codificata tre terzine ATA, ATC E A.T.T.. Motivi UN, CON E T, terzo nei codoni per IO, hanno un simbolo comune N, quindi il codone generalizzato dell'isoleucina si scrive come segue: ATN. Tutte queste caratteristiche del codice sono ben illustrate dalla tabella sopra.
È curioso che il peso molecolare dell'amminoacido codificato dipenda inversamente dal numero del gruppo degenerato a cui appartiene (V. Shcherbak). Questa è la prima prova qui notata dell'evidente coinvolgimento della massa molecolare dei componenti del codice genetico nella sua organizzazione razionale.
Nella tabella sopra, l'ordinamento per peso molecolare crescente si riferisce agli amminoacidi nella composizione ordinati per numero di gruppi di degenerazione (numeri romani), raggruppati in due ottetti (numeri arabi). In questo caso, la posizione della cisteina CON corretto, di cui si parlerà nel prossimo capitolo; Parleremo anche di ottetti lì.
Ritornando alla scelta venti amminoacidi per la codifica, vale la pena notare un'altra circostanza interessante: questa scelta potrebbe essere determinata anche dalla teoria dell'informazione quantistica, che propone un algoritmo ottimale (algoritmo di Grover) per impacchettare e leggere il contenuto informativo del DNA (Apoorva Patel, 2001). Questo algoritmo determina il numero di oggetti N, distinti per il numero di risposte Non proprio alle domande Q, nel seguente modo:
(2Q +1) sin -1 (1 / ?N ) = ? /2 .
Soluzioni di questa equazione per piccoli valori Q molto caratteristico:
Q= 1 ln N= 04.0
Q= 2 ln N= 10.5
Q= 3 ln N= 20.2.
In teoria, questi valori non devono essere numeri interi. È interessante notare che, in prima approssimazione, corrispondono alla sequenza dei numeri tetraedrici, nonché all'evoluzione della dimensione del codone funzionale da singoletto a tripletto. In altre parole, un tetraedro può essere costruito anche da dieci e da quattro monomeri; Questi numeri sono contrassegnati nelle soluzioni dell'equazione precedente. Successivamente mostreremo che la combinazione dei parametri dimensionali di amminoacidi e nucleotidi, in base alle regole da noi proposte, porta all'equilibrio spaziale di un tetraedro di venti monomeri corrispondenti a questi amminoacidi. Qui vale forse la pena ricordare le parole ancora attuali di V?se (1973): “ Sembra quasi uno scherzo crudele che la Natura scelga un numero del genere[codificato] aminoacidi, che si ottiene facilmente come risultato di molti
operazioni matematiche" Ma, in un modo o nell'altro, venti alfa aminoacidi (su centinaia presenti in natura) si sono rivelati sufficienti per fornire la necessaria diversità di proteine.
…………………
Numero 496 , che caratterizza questo capitolo, è interessante in quanto appartiene alla classe dei cosiddetti numeri perfetti e questa è l'unica cosa tre cifre numero perfetto. Un numero perfetto è un numero naturale uguale alla somma di tutti i suoi divisori (cioè di tutti i divisori positivi diversi dal numero stesso). Somma di tutti i divisori di un numero 496 , cioè 1+2+4+8+16+31+62+124+248, è uguale a se stesso. Abbiamo ricordato i numeri perfetti e notato l'unicità di questo particolare numero, perché, in primo luogo, è a tre cifre, come gli elementi di codifica a tre cifre di cui stiamo parlando, e in secondo luogo, come tutti i numeri qui menzionati in precedenza, è casuale o no – caratterizza uno dei parametri formali del codice genetico, di cui parleremo più avanti. La pazienza del lettore non è illimitata, e l’Autore ricorda a questo proposito un estratto di una lettera di uno dei lettori al famoso divulgatore di matematica Martin Gardner: Smettila di cercare numeri interessanti! Lascia almeno un numero non interessante per gli interessi! Ma la tentazione è grande ed è difficile resistere.
Dal libro Il più recente libro dei fatti. Volume 1 [Astronomia e astrofisica. Geografia e altre scienze della terra. Biologia e Medicina] autore Dal libro Viaggio nel passato autore Golosnitsky Lev PetrovichVenticinque milioni di anni fa Fa caldo in un pomeriggio di luglio nella steppa del Kazakistan. Tutto è inondato di luce solare: una pianura collinare, laghi situati in depressioni e bordati da canneti, zone gialle di sabbia ricoperte di saxaul.Le colline scendono ripide verso i laghi
Dal libro Mafia farmaceutica e alimentare di Brouwer-LouisVenti principali motivi di esenzione dal servizio militare in tutti i centri di reclutamento per il 1986 N. Malattie e condizioni patologiche Numero di esentati dal servizio militare Rapporto tra esentati dal servizio militare e persone abili al servizio
Dal libro IL TIMBRO DEL CREATORE. Ipotesi sull'origine della vita sulla Terra. autore Filatov Felix PetrovichCapitolo 496. Perché ci sono venti amminoacidi codificati? (XII) Al lettore inesperto può sembrare che gli elementi della macchina di codificazione genetica siano stati descritti nel capitolo precedente in modo così dettagliato che alla fine della lettura cominciò addirittura a stancarsi, sentendosi un po' stanco
Dal libro La password delle antenne incrociate autore Khalifman Joseph AronovichVENTICINQUE ANNI DOPO Gli anni passano e la minuscola camera embrionale, grande quanto un ditale, perduta nel terreno cresce e diventa un tumulo evidente. È strettamente rivestito in alto di argilla, sabbia, cemento, e in questo blocco, morto all'esterno e muto come pietra, scorre
Dal libro Il più recente libro dei fatti. Volume 1. Astronomia e astrofisica. Geografia e altre scienze della terra. Biologia e medicina autore Kondrashov Anatoly PavlovichCosa significa l'espressione “venticinquesimo fotogramma”? Questo termine è apparso per la prima volta a metà del secolo scorso negli Stati Uniti e si riferiva al cinema. Il fatto è che una cinepresa e, di conseguenza, una cinepresa per proiezione, fanno avanzare la pellicola a una velocità di 24 fotogrammi al secondo. Ma nel 1957
Dal libro Chimica biologica autore Lelevich Vladimir Valeryanovich Dal libro dell'autoreCapitolo 23. Metabolismo degli aminoacidi. Stato dinamico delle proteine del corpo L'importanza degli aminoacidi per il corpo risiede principalmente nel fatto che vengono utilizzati per la sintesi delle proteine, il cui metabolismo occupa un posto speciale nei processi metabolici tra il corpo e
Dal libro dell'autoreAssorbimento degli aminoacidi. Avviene mediante trasporto attivo con la partecipazione dei trasportatori. La concentrazione massima di aminoacidi nel sangue viene raggiunta 30-50 minuti dopo aver consumato un pasto proteico. Il trasferimento attraverso il bordo del pennello viene effettuato da un numero di vettori, molti
Dal libro dell'autoreDisturbi ereditari del trasporto degli aminoacidi La malattia di Hartnup è un disturbo dell'assorbimento del triptofano nell'intestino e del suo riassorbimento nei tubuli renali. Poiché il triptofano funge da prodotto di partenza per la sintesi della vitamina PP, le principali manifestazioni della malattia di Hartnup sono
Dal libro dell'autoreVie del metabolismo degli aminoacidi nei tessuti Gli aminoacidi sono composti bifunzionali contenenti un gruppo amminico e uno carbossilico. Le reazioni in questi gruppi sono comuni a vari amminoacidi. Questi includono: 1. sul gruppo amminico – reazioni di deaminazione e
Dal libro dell'autoreTransaminazione degli amminoacidi La transaminazione è la reazione di trasferimento di un gruppo a-amminico da un amminoacido a un a-chetoacido, con conseguente formazione di un nuovo chetoacido e di un nuovo amminoacido. Le reazioni sono catalizzate dagli enzimi aminotransferasi. Questi sono enzimi complessi, coenzima
Dal libro dell'autoreDeaminazione degli amminoacidi La deaminazione degli amminoacidi è la reazione di eliminazione di un gruppo amminico da un amminoacido con rilascio di ammoniaca. Esistono due tipi di reazioni di deaminazione: diretta e indiretta. La deaminazione diretta è l'eliminazione diretta di un gruppo amminico da
Dal libro dell'autoreDeaminazione indiretta degli amminoacidi La maggior parte degli amminoacidi non è in grado di effettuare la deaminazione in un unico passaggio, come il glutammato. I gruppi amminici di tali aminoacidi vengono trasferiti al β-chetoglutarato per formare acido glutammico, che viene poi sottoposto a
Dal libro dell'autoreDecarbossilazione degli amminoacidi Alcuni amminoacidi e i loro derivati possono subire decarbossilazione. Le reazioni di decarbossilazione sono irreversibili e sono catalizzate dagli enzimi decarbossilasi, che richiedono piridossal fosfato come coenzima.
Dal libro dell'autoreCapitolo 25. Metabolismo dei singoli amminoacidi Metabolismo della metionina La metionina è un amminoacido essenziale. Il gruppo metilico della metionina è un frammento mobile monocarbonio utilizzato per la sintesi di numerosi composti. Trasferimento del gruppo metilico della metionina al corrispondente
Ogni organismo vivente ha un insieme speciale di proteine. Alcuni composti nucleotidici e la loro sequenza nella molecola del DNA formano il codice genetico. Trasmette informazioni sulla struttura della proteina. Un certo concetto è stato accettato in genetica. Secondo esso, un gene corrispondeva a un enzima (polipeptide). Va detto che la ricerca sugli acidi nucleici e sulle proteine è stata condotta per un periodo abbastanza lungo. Più avanti nell'articolo daremo uno sguardo più da vicino al codice genetico e alle sue proprietà. Verrà inoltre fornita una breve cronologia della ricerca.
Terminologia
Il codice genetico è un modo di codificare la sequenza di proteine aminoacidiche che coinvolgono la sequenza nucleotidica. Questo metodo di generazione di informazioni è caratteristico di tutti gli organismi viventi. Le proteine sono sostanze organiche naturali ad elevata molecolarità. Questi composti sono presenti anche negli organismi viventi. Sono costituiti da 20 tipi di aminoacidi, chiamati canonici. Gli amminoacidi sono disposti in una catena e collegati in una sequenza rigorosamente stabilita. Determina la struttura della proteina e le sue proprietà biologiche. Ci sono anche diverse catene di aminoacidi in una proteina.

DNA e RNA
L'acido desossiribonucleico è una macromolecola. È responsabile della trasmissione, archiviazione e implementazione delle informazioni ereditarie. Il DNA utilizza quattro basi azotate. Questi includono adenina, guanina, citosina, timina. L'RNA è costituito dagli stessi nucleotidi, tranne che contiene timina. Invece, c'è un nucleotide contenente uracile (U). Le molecole di RNA e DNA sono catene di nucleotidi. Grazie a questa struttura si formano sequenze: l'“alfabeto genetico”.
Implementazione delle informazioni
La sintesi proteica, codificata dal gene, viene realizzata combinando l'mRNA su uno stampo di DNA (trascrizione). Anche il codice genetico viene trasferito nella sequenza aminoacidica. Cioè, avviene la sintesi della catena polipeptidica sull'mRNA. Per crittografare tutti gli aminoacidi e il segnale per la fine della sequenza proteica sono sufficienti 3 nucleotidi. Questa catena è chiamata tripletta.

Storia dello studio
Lo studio delle proteine e degli acidi nucleici è stato effettuato per molto tempo. A metà del XX secolo apparvero finalmente le prime idee sulla natura del codice genetico. Nel 1953 si scoprì che alcune proteine sono costituite da sequenze di aminoacidi. È vero, a quel tempo non potevano ancora determinare il loro numero esatto e c'erano numerose controversie al riguardo. Nel 1953 furono pubblicati due lavori degli autori Watson e Crick. Il primo parlava della struttura secondaria del DNA, il secondo parlava della sua copia ammissibile utilizzando la sintesi del modello. Inoltre, è stata posta enfasi sul fatto che una specifica sequenza di basi è un codice che trasporta informazioni ereditarie. Il fisico americano e sovietico Georgiy Gamow ipotizzò l'ipotesi della codifica e trovò un metodo per testarla. Nel 1954 fu pubblicato il suo lavoro, durante il quale propose di stabilire corrispondenze tra le catene laterali degli amminoacidi e i "buchi" a forma di diamante e di utilizzarli come meccanismo di codifica. Quindi fu chiamato rombico. Spiegando il suo lavoro, Gamow ha ammesso che il codice genetico potrebbe essere una tripletta. Il lavoro del fisico fu uno dei primi tra quelli considerati vicini alla verità.

Classificazione
Nel corso degli anni sono stati proposti diversi modelli di codici genetici, di due tipi: sovrapposti e non sovrapposti. Il primo era basato sull'inclusione di un nucleotide in diversi codoni. Include un codice genetico triangolare, sequenziale e maggiore-minore. Il secondo modello presuppone due tipi. I codici non sovrapposti includono il codice combinato e il codice senza virgole. La prima opzione si basa sulla codifica di un amminoacido da parte di triplette di nucleotidi e la cosa principale è la sua composizione. Secondo il "codice senza virgole", alcune triplette corrispondono ad aminoacidi, ma altre no. In questo caso si è ritenuto che se alcune terzine significative fossero state disposte in sequenza, altre collocate in una diversa cornice di lettura non sarebbero state necessarie. Gli scienziati credevano che fosse possibile selezionare una sequenza nucleotidica che soddisfacesse questi requisiti e che esistessero esattamente 20 triplette.

Sebbene Gamow e i suoi coautori mettessero in dubbio questo modello, nei successivi cinque anni fu considerato il più corretto. All'inizio della seconda metà del XX secolo apparvero nuovi dati che permisero di scoprire alcune carenze nel “codice senza virgole”. Si è scoperto che i codoni sono in grado di indurre la sintesi proteica in vitro. Più vicino al 1965, fu compreso il principio di tutte le 64 terzine. Di conseguenza, è stata scoperta la ridondanza di alcuni codoni. In altre parole, la sequenza aminoacidica è codificata da diverse triplette.
Caratteristiche distintive
Le proprietà del codice genetico includono:

Variazioni
La prima deviazione del codice genetico dallo standard fu scoperta nel 1979 durante lo studio dei geni mitocondriali nel corpo umano. Ulteriori varianti simili sono state ulteriormente identificate, inclusi molti codici mitocondriali alternativi. Questi includono la decodifica del codone di stop UGA, che viene utilizzato per determinare il triptofano nei micoplasmi. GUG e UUG negli archaea e nei batteri sono spesso utilizzati come opzioni di partenza. A volte i geni codificano per una proteina con un codone iniziale diverso da quello normalmente utilizzato dalla specie. Inoltre, in alcune proteine, la selenocisteina e la pirrolisina, che sono aminoacidi non standard, sono inseriti nel ribosoma. Legge il codone di stop. Questo dipende dalle sequenze trovate nell'mRNA. Attualmente la selenocisteina è considerata il 21° e il pirrolisano il 22° aminoacido presente nelle proteine.
Caratteristiche generali del codice genetico
Tuttavia, tutte le eccezioni sono rare. Negli organismi viventi, il codice genetico ha generalmente una serie di caratteristiche comuni. Questi includono la composizione di un codone, che comprende tre nucleotidi (i primi due appartengono a quelli che definiscono), il trasferimento dei codoni da parte del tRNA e dei ribosomi nella sequenza aminoacidica.
Quando è necessario sintetizzare le proteine, prima che la cellula sorga un problema serio: le informazioni nel DNA vengono immagazzinate sotto forma di una sequenza codificata 4 caratteri(nucleotidi) e le proteine sono costituite da 20 simboli diversi(aminoacidi). Se provi a utilizzare tutti e quattro i simboli contemporaneamente per codificare gli aminoacidi, otterrai solo 16 combinazioni, mentre gli aminoacidi proteogenici sono 20. Non ce ne sono abbastanza...
C’è un esempio di pensiero brillante su questo argomento:
"Prendiamo, ad esempio, un mazzo di carte da gioco, in cui prestiamo attenzione solo al seme della carta. Quante triplette dello stesso tipo si possono ottenere? Quattro, ovviamente: tre di cuori, tre di quadri, tre di picche e tre di fiori. Quante triplette ci sono con due carte dello stesso seme e una di seme diverso? Diciamo che abbiamo quattro scelte per la terza carta. Quindi abbiamo 4x3 = 12 possibilità. Inoltre abbiamo quattro terzine con tutte e tre le carte diverse. Quindi, 4+12+4=20, e questo è l'esatto numero di aminoacidi che volevamo ottenere" (George Gamow, ing. George Gamow, 1904-1968, fisico teorico, astrofisico e divulgatore scientifico sovietico e americano) .
Infatti, gli esperimenti hanno dimostrato che per ogni amminoacido esistono due nucleotidi obbligatori e un terzo variabile, meno specifico (“ effetto dondolo"). Se prendi tre caratteri su quattro, ottieni 64 combinazioni, che superano notevolmente il numero di amminoacidi. Pertanto, si scopre che qualsiasi amminoacido è codificato da tre nucleotidi. Questo trio è chiamato codone. Come già accennato, ci sono 64 opzioni. Tre di essi non codificano per alcun amminoacido; questi sono i cosiddetti " codoni senza senso"(Francese) senza senso- sciocchezze) o "codoni di stop".
Codice genetico
Il codice genetico (biologico) è un modo per codificare le informazioni sulla struttura delle proteine sotto forma di sequenza nucleotidica. È progettato per tradurre il linguaggio di quattro caratteri dei nucleotidi (A, G, U, C) nel linguaggio di venti caratteri degli amminoacidi. Ha caratteristiche caratteristiche:
- Triplice– tre nucleotidi formano un codone che codifica per un amminoacido. Ci sono un totale di 61 codoni di senso.
- Specificità(O univocità) – ogni codone corrisponde a un solo amminoacido.
- Degenerazione– un amminoacido può corrispondere a più codoni.
- Versatilità– il codice biologico è lo stesso per tutti i tipi di organismi sulla Terra (ci sono però delle eccezioni nei mitocondri dei mammiferi).
- Colinearità– la sequenza dei codoni corrisponde alla sequenza degli aminoacidi nella proteina codificata.
- Non sovrapponibile– Le terzine non si sovrappongono tra loro, essendo posizionate una accanto all’altra.
- Nessuna punteggiatura– non ci sono nucleotidi aggiuntivi o altri segnali tra le triplette.
- Unidirezionalità– durante la sintesi proteica, i codoni vengono letti in sequenza, senza saltare o tornare indietro.
Tuttavia è chiaro che il codice biologico non può esprimersi senza ulteriori molecole che svolgano una funzione di transizione o funzione dell'adattatore.
Ruolo adattatore degli RNA di trasferimento
Gli RNA di trasferimento sono l'unico intermediario tra la sequenza di acido nucleico di 4 lettere e la sequenza proteica di 20 lettere.
Ciascun RNA di trasferimento ha una specifica sequenza di triplette nell'ansa dell'anticodone ( anticodone) e può attaccare solo un amminoacido che corrisponde a questo anticodone. È la presenza dell'uno o dell'altro anticodone nel tRNA che determina quale amminoacido sarà incluso nella molecola proteica, perché né il ribosoma né l'mRNA riconoscono l'amminoacido.
Così, ruolo adattatore del tRNAÈ:
- nel legame specifico con gli aminoacidi,
- in particolare, secondo l'interazione codone-anticodone, il legame con l'mRNA,
- e, di conseguenza, nell'incorporazione degli aminoacidi nella catena proteica secondo le informazioni contenute nell'mRNA.
L'aggiunta di un amminoacido al tRNA viene effettuata da un enzima aminoacil-tRNA sintetasi, che ha specificità per due composti contemporaneamente: qualsiasi amminoacido e il suo corrispondente tRNA. La reazione richiede due legami ATP ad alta energia. L'amminoacido si attacca all'estremità da 3" del circuito accettore del tRNA attraverso il suo gruppo α-carbossilico e il legame tra l'amminoacido e il tRNA diventa macroergico. Il gruppo α-amminico rimane libero.